Hôm qua mình có làm speaker chia sẻ về kiến trúc hệ thống Log của Teamcrop.com, thấy nhiều bạn hưởng ứng và quan tâm quá nên mình khai trương blog năm mới bằng một bài viết ngắn nói về chủ đề này.

Xây dựng hệ thống log được đánh giá rất quan trọng, đặc biệt đối với các hệ thống đang trong giai đoạn tăng trưởng người dùng và mở rộng tính năng. Có nhiều hướng tiếp cận khác nhau để triển khai hệ thống log, từ việc sử dụng các dịch vụ Saas có sẵn, không cần cài đặt hay server gì như các hệ thống Loggly, DataDog, Papertrail…cho tới các open source như Graylog, ELK (ElasticSearch, Logstash, Kibana) Stack, Grafana…Tuy nhiên, do đặc thù của dữ liệu, số lượng log và tốc độ truy xuất mà Teamcrop buộc phải thiết kế một hệ thống log riêng để giải quyết các vấn đề về chi phí lưu trữ và vận hành.
Để xây dựng hoặc tìm hiểu một hệ thống Log, chúng ta cần thấy được các thành phần của hệ thống Logging bởi performance và tính tiện dụng đều dựa vào mô hình hệ thống Log. Mình tạm chia một hệ thống Log thành ba thành phần cơ bản là Collector, Storage và Dashboard.

- Collector là phân hệ chịu trách nhiệm thu thập dữ liệu log từ các nguồn cung cấp (syslog, access log, error log, api request, sql query..)
- Storage là thành phần sẽ lưu trữ dữ liệu log, có thể là tạm thời hoặc vĩnh viễn, ví dụ như RabbitMQ (tạm thời), File System (tạm thời), MySQL, Clickhouse…
- Dashboard là thành phần sẽ truy xuất vào storage và hiển thị dữ liệu bao gồm data table, biểu đồ, dashboard…đến đối tượng cần coi log.
Để dễ dàng tiếp cận với các vấn đề của Log, trước tiên chúng ta cần phân loại log vì mỗi loại log sẽ có đặc tính khác nhau về số lượng cũng như cách truy xuất, sử dụng. Mình tạm phân loại Log thành 2 loại: Business và Operation Log.
Business Log
Business Log là những loại log giúp hỗ trợ các hoạt động và quyết định của doanh nghiệp. Như các Usage Log liên quan đến sử dụng các tính năng trên giao diện để bộ phận marketing, product dễ dàng ra quyết định liên quan đến kinh doanh và phát triển sản phẩm. Đối với loại log này thì hiện tại có ông trùm và được sử dụng khá nhiều là Google Analytics. Nếu cần open source thì có thể sử dụng Matomo (tiền thân là Piwik) để cài đặt trên server của bạn, tính năng của Matomo cũng gần như Google Analtyics.
Một loại Business Log khác mà mình đề cập trong phần chia sẻ là Critical Function Log dành cho những nghiệp vụ quan trọng, giúp đảm bảo an toàn cho hệ thống và khôi phục được trong trường hợp sự cố xảy ra và có thể tạo được dữ liệu. Log này quan trọng vì trong một kiến trúc Microservices thì có thể do cấu hình, cài đặt hoặc lỗi hệ thống khiến cho 1 service có thể bị cô lập và không gọi được các service khác trong quá trình thực thi. Ví dụ như tạo đơn hàng (service Đơn hàng) sẽ gọi các service như Sản phẩm, Tồn kho, Khách hàng, Thu chi…để hỗ trợ quá trình tạo đơn hàng. Nếu trong quá trình tạo đơn hàng mà toàn bộ các service khác không thể truy cập thì service Đơn hàng sẽ có một cơ chế an toàn riêng để đảm bảo dữ liệu request lên (raw POST data) được backup tạm thời phòng trường hợp cực hạn này. Số lượng tính năng áp dụng cơ chế log này là không lớn.
Loại log cuối cùng trong nhóm Business Log mà mình muốn đề cập là Auditing Log. Loại log này khá là quan trọng và nếu bạn đang phát triển các hệ thống Enterprise không thể bỏ qua. Auditing Log giúp doanh nghiệp có thể dễ dàng phát hiện các hoạt động bất thường, quan trọng (như xóa, import, export dữ liệu…) để kịp thời có hướng xử lý. Auditing Log còn có thể thiết kế như một hệ thống Change Log để lưu lại lịch sử thay đổi dữ liệu của 1 record (như đơn hàng, khách hàng…). Nếu có tìm hiểu về Microservices thì các bạn sẽ thấy cách thức lưu change log này của Auditing Log khá giống với pattern Event Sourcing (ES) trong mô hình CQRS/ES.
Trong hầu hết trường hợp thì chúng ta ít khi tập trung vào tự xây dựng business log bởi đối với loại này phải được phân tích kỹ và chỉ định cụ thể dịch vụ nào, tính năng nào cần được log (Auditting, Critical, Usage) để tiến hành lập trình nâng cấp.
Operation Log
Nhóm log thứ hai được đánh giá là có tác động to lớn đến quá trình tối ưu, cải tiến hệ thống là Operation Log. Một số loại log thuộc nhóm này bao gồm: Operating System, General Log, API Request, SQL Query và Distributed Tracing.
Operating System Log là nhóm log cơ bản giúp theo dõi và đánh giá tình hình chung của hệ thống như ổ cứng, memory, cpu, network IO…đối với nhóm log này thường đi kèm với hệ thống monitoring và bên Teamcrop sử dụng NodeQuery.com để theo dõi vì hệ thống NodeQuery khá tốt và đơn giản, kèm với giao diện dashboard rất dễ dùng và cơ chế alert hiệu quả. NodeQuery cũng được rất nhiều công ty trên thế giới sử dụng.
Loại log tiếp theo trong nhóm Operation Log là General Log, bao gồm những Log liên quan đến hoạt động của Nginx, PHP…và những custom log message do bạn ghi xuống trong quá trình vận hành hoặc debug hệ thống. Cùng với API Request Log, SQL Query Log thì mình tự xây dựng cơ chế log riêng bởi số lượng và tần suất log rất cao, việc sử dụng các hệ thống khác hoàn toàn không hiệu quả về hiệu suất và kinh tế.
API Request Log là loại log để theo dõi toàn bộ các request vào hệ thống Microservices. Giúp bộ phận lập trình biết được performance của các request như thời gian thực thi một tính năng (execution time) cũng như memory cấp phát cho các tính năng.
SQL Query Log cũng là loại log có mục đích khá giống với API Request Log, giúp lập trình viên và DB Admin có thể theo dõi được tình hình truy vấn database, câu truy vấn nào chưa tối ưu, table nào được truy cập nhiều, tình trạng tỷ lệ master/slave trong mô hình replicate có duy trì ở mức ổn định hay không…
Cuối cùng là một loại log cực kỳ cần thiết trong quá trình vận hành một hệ thống Microservices, đó là Distributed Tracing. Hầu hết các bạn khi chuyển sang kiến trúc Microservices, sẽ hay bị trình trạng service gọi lồng vào nhau, A –> B —> C —> D thì khi có một lỗi hoặc bottleneck nào đó ở một service bên trong (vd service C) thì rất khó phát hiện và debug bởi đặc thù phân tán của kiến trúc Microservices. Để giải quyết vấn đề này thì kỹ thuật Distributed Tracing sẽ giúp ích rất nhiều. Teamcrop sử dụng Zipkin Library PHP dùng để format dữ liệu theo đặc tả OpenTracing và backend sử dụng Jaeger (dự án Open source của Uber).
Đó là toàn bộ những chia sẻ của Tuấn tại buổi meetup đầu năm 2020 ngày 09/01/2020. Bên dưới là phần Slide trình bày (có cải tiến cho dễ hiểu hơn).
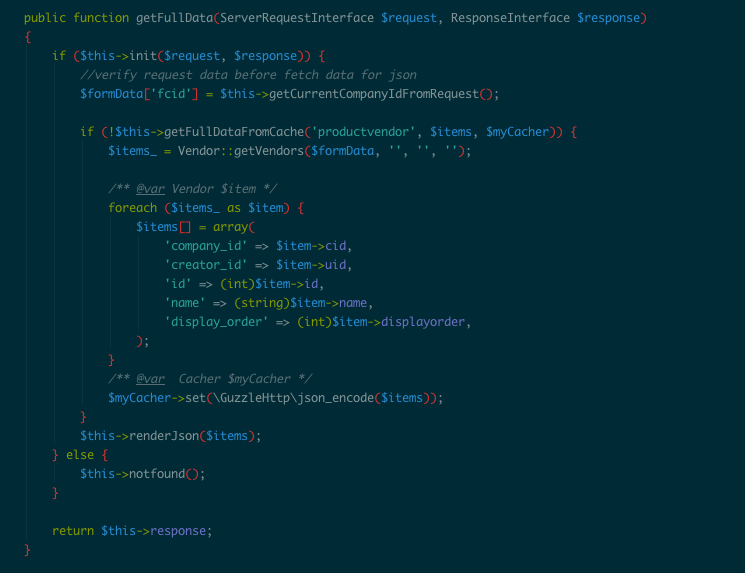
Dưới đây là schema của 3 table tương tứng với 3 loại log (General Log, API Request Log và SQL Query Log) được tạo trong database ClickHouse:
CREATE TABLE log_request ( lr_date Date, lr_datetime DateTime, lr_hour UInt8, lr_minute UInt8, lr_service String, lr_method String, lr_controller String, lr_action String, lr_companyid UInt32, lr_userid UInt32, lr_status UInt16, lr_exectime Float32, lr_memory Float32, lr_ip String, lr_depth UInt8, lr_source String, lr_traceid String, lr_tracespanid String ) ENGINE = MergeTree(lr_date, (lr_datetime, lr_hour, lr_minute, lr_service, lr_method, lr_controller, lr_action, lr_companyid, lr_userid, lr_status, lr_exectime, lr_memory, lr_ip, lr_depth, lr_source, lr_traceid, lr_tracespanid), 8192);; CREATE TABLE log_sql ( ls_date Date, ls_datetime DateTime, ls_hour UInt8, ls_minute UInt8, ls_hosttype String, ls_host String, ls_querytype String, ls_table String, ls_exectime Float32, ls_companyid UInt32, ls_userid UInt32, ls_traceid String, ls_tracespanid String ) ENGINE = MergeTree(ls_date, (ls_datetime, ls_hour, ls_minute, ls_hosttype, ls_host, ls_querytype, ls_table, ls_exectime, ls_companyid, ls_userid, ls_traceid, ls_tracespanid), 8192); CREATE TABLE log_syslog ( ls_date Date, ls_datetime DateTime, ls_hour UInt8, ls_minute UInt8, ls_message String, ls_tag String, ls_host String, ls_source String ) ENGINE = MergeTree(ls_date, (ls_datetime, ls_hour, ls_minute, ls_message, ls_tag, ls_host, ls_source), 8192);
P.S: Teamcrop.com là hệ thống phần mềm quản lý bán hàng và nhân sự, nếu bạn nào quan tâm thì có thể dùng thử và ủng hộ một startup hoàn toàn Việt Nam nhé. Nếu bạn nào hứng thú với PHP hoặc kiến trúc Microservices, thì có thể cùng tham gia xây dựng Teamcrop với Tuấn, mọi thông tin gửi vào email trong trang cuối của Slide ở trên nhé.