Cũng hơn một tháng kể từ bài viết gần nhất, nay mới có thời gian ngồi viết lách tiếp. Dạo gần đây thường release các dự án outsource nên cũng hay làm documentation cũng như mở các dự án mới nên việc setup CI/CD thường xuyên hơn và chân tay hơn. Thấy các kiến thức này hay nên hôm nay mình sẽ chia sẻ mọi người quy trình CI/CD bên mình áp dụng cho “đại dự án” Teamcrop cũng như các dự án outsourcing mà Moout thực hiện.
CI/CD là gì?
Bạn sẽ thấy có nhiều định nghĩa từ hai lúa cho đến hàn lâm cho khái niệm CI/CD. Mình sẽ dùng cách định nghĩa của mình để mọi người dễ hiểu theo cách thông thường nhất. CI/CD là một bộ đôi công việc, bao gồm CI (Continuous Integration) và CD (Continuous Delivery), ý nói là quá trình tích hợp (integration) thường xuyên, nhanh chóng hơn khi code cũng như thường xuyên cập nhật phiên bản mới (delivery).
Tại sao phải quan tâm đến CI/CD?
Ngày nay, với xu hướng agile/lean dẫn đến việc phát triển tính năng là điều bình thường, quan trọng phải là thần thái, ý lộn, quan trọng là phải nhanh. Nếu một tính năng mà mất 2, 3 tháng mới release thì dẫn đến nhiều hệ lụy như làm không phù hợp nhu cầu khách hàng, hoặc đối thủ đã ra mắt trước đó, mất đi cái lợi thế dẫn đầu. Do đó, việc làm ra một sản phẩm, tính năng đòi hỏi thần tốc là ưu tiên số một hiện nay.
Bên cạnh đó, để nhanh chóng ra mắt một tính năng, phiên bản mới nếu theo cách cổ điển sẽ mất nhiều thời gian bởi công việc chân tay khá nhiều và mỗi lần release cũng huy động một cơ số người không nhỏ để cập nhật một thay đổi dù là nhỏ nhất. Bởi vậy, xu hướng CI/CD giúp cung cấp các framework, workflow giúp tiết kiệm thời gian, nguồn lực của quá trình release (delivery).
Quy trình CI/CD tham khảo
Có rất nhiều quy trình, công cụ khác nhau để ứng dụng CI/CD vào dự án. Nội dung của bài viết này dựa trên kinh nghiệm cho các dự án của mình triển khai cũng như đặc thù là các hệ thống web, và viết bằng PHP (PHP hoặc Python hoặc abc…không quá quan trọng trong ngữ cảnh chia sẻ về CI/CD).
Dưới đây là các bước thông thường của quá trình release tính năng trong một dự án thuộc hệ thống Teamcrop.
– Bước 1: [Manual] Khởi tạo repository và có branch default là master và dev. Cài đặt trên Gitlab 9.
– Bước 2: [Manual] Trừ owner ra, thì các coder sẽ push code tính năng lên branch dev
– Bước 3: [Auto] Hệ thống tự động thực hiện test source code, nếu PASS thì sẽ deploy tự động (rsync) code lên server beta.
– Bước 4: [Manual] Tester/QA sẽ vào hệ thống beta để làm UAT (User Acceptance Testing) và confirm là mọi thứ OK.
– Bước 5: [Manual] Coder hoặc owner sẽ vào tạo Merge Request, và merge từ branch dev sang branch master.
– Bước 6: [Manual] Owner sẽ accept merge request.
– Bước 7: [Auto] Hệ thống sẽ tự động thực hiện test source code, nếu PASS sẽ enable tính năng cho phép deploy lên production server.
– Bước 8: [Manual] Owner review là merge request OK, test OK. Tiến hành nhấn nút để deploy các thay đổi lên môi trường production.
– Bước 9: [Manual] Tester/QA sẽ vào hệ thống production để làm UAT và confirm mọi thứ OK. Nếu không OK, Owner có thể nhấn nút Deploy phiên bản master trước đó để rollback hệ thống về trạng thái stable trước đó.
– Bước 10: [Manual] Thắp nhang và hy vọng khách hàng không chửi rủa hoặc email complain.
Áp dụng CI/CD với Gitlab 9
Trong khuôn khổ bài viết này, mình sẽ hướng dẫn mọi người cài đặt Gitlab 9 để quản lý source code, và trên công nghệ Git. Đòi hỏi của tất cả setup này là trên server đã cài Docker, nếu các bạn chưa có docker trên server thì có thể tham khảo các bài viết về docker trên bloghoctap cũng như tìm kiếm thêm trên google.
Tại sao phải là Gitlab 9?
Đây là câu hỏi hay, bởi vì trước đó bên mình sử dụng Gitlab 8, tuy nhiên, do các hạn chế về UI/UX cũng như không tích hợp ngon lành vụ CI/CD nên khi bản 9 ra mắt, mình đã thử sử dụng và thấy bản 9 phù hợp hơn cho workflow nên quyết định dọn dẹp sang Gitlab 9.
Cài đặt Gitlab 9 với docker
Bạn chạy câu lệnh sau để tạo một container chứa Gitlab 9.
docker run --detach \
--hostname code.teamcrop.com \
--publish 8080:80 --publish 2222:22 \
--name gitlab9 \
--restart=always \
--volume /gitlab9/config:/etc/gitlab \
--volume /gitlab9/logs:/var/log/gitlab \
--volume /gitlab9/data:/var/opt/gitlab \
gitlab/gitlab-ce:9.0.3-ce.0
Nếu ai từng dùng docker sẽ hiểu ý nghĩa câu lệnh trên. Đơn giản là mình sử dụng image gitlab/gitlab-ce:9.0.3-ce.0. Có mount ra 3 thư mục bên ngoài máy ở thục mục /gitlab9 để lỡ có chuyện gì chỉ cần stop, remove container, khi chạy docker run lại thì không bị mất dữ liệu, source code. Câu lệnh trên có map 2 port là 8080 và 2222 tương ứng tới 2 port 80 và 22 trong container. Mình mapping port vậy bởi vì trên server dev này có rất nhiều service khác và đã chiếm port 80 và 22 (ssh ^^!).
Sau khi bạn start container thì có thể truy cập vào từ ip hoặc domain (mà bạn đã trỏ DNS), ví dụ: http://code.teamcrop.com:8080 là có thể vào gitlab 9, tài khoản mặc định là `root`.
Không có gì cao siêu ở cài đặt này, có thể tham khảo thêm ở trang chủ của Gitlab.com nhé.
Quản lý sourcecode bằng Gitlab
Về phần này thì mình không cần nói dài dòng, cũng như một hệ thống git thông thường (như github..), bạn có thể tìm hiểu thêm về git và Gitlab để team có thể cùng làm việc và quản lý sourcecode trên Gitlab.
CI/CD với Gitlab CI
Thông thường, các hệ thống quản lý sourcecode không kèm theo cơ chế CI/CD. Nếu bạn muốn triển khai thì buộc phải liên kết đến repository, phân quyền đủ kiểu để hệ thống đó có thể lấy source code từ respository. Trước đây bên mình sử dụng Jenkins cho việc này. Tuy nhiên, từ khi Gitlab ra mắt tính năng Gitlab CI, kèm theo sự chậm chạp, rắc rối và rề rề của Jenkins thì mình quyết định chia tay với Jenkins và đến với Gitlab CI luôn, và quả là một bộ đôi hoàn hảo. Code để ở Gitlab, rồi trong đó có cho cài đặt CI/CD để test và deploy code tự động.
Cũng như một số bạn mới lần đầu tiếp xúc với Gitlab CI, mình đã từng thấy nó khó hiểu và cao siêu vì setup tùm lum. Rồi setup xong lại không biết nó chạy thế nào, cơ chế deploy source code ra sao. Tuy nhiên, sau một vài “va chạm” đầy mồ hôi và nước mắt thì cũng nắm và hiểu được cách Gitlab CI vận hành, và nay chia sẻ cho mọi người để vận dụng cho workflow của mình.
Để dùng được Gitlab CI thì bạn cần có 2 thành phần sau: file `.gitlab-ci.yml` nằm ở thư mục gốc của dự án và Gitlab Runner.
File .gitlab-ci.yml là gì?
Mặc định Gitlab không có cơ chế nào về CI cho dự án của bạn, chỉ khi nào dự án của bạn có file .gitlab-ci.yml nằm ở thư mục gốc thì Gitlab mới nhận dạng được dự án của bạn muốn áp dụng Gitlab CI. File này có định dạng và cần hợp lệ thì mới có thể hoạt động được, không thì khi bạn push code lên thì Gitlab sẽ báo lỗi file định dạng nội dung của file cấu hình không hợp lệ. Tham khảo cú pháp của cấu hình này tại https://docs.gitlab.com/ce/ci/yaml/
Trong file này có gì? File này có một số section để khai báo như trước khi chạy test thì làm gì, khi test thì thực hiện lệnh gì (vd chạy linter check cú pháp, chạy PHPUnit test…), test xong rồi thì thực hiện deploy đi đâu (beta, production..) với câu lệnh gì (vd: rsync..). Tùy đặc thù ngôn ngữ lập trình, cách đóng gói của dự án mà sẽ có các lệnh tương ứng thực hiện.
Tới đây các bạn sẽ có câu hỏi là vậy cái gì sẽ chạy, thực thi các câu lệnh, chỉ dẫn trong file config trên? Hay là Gitlab Server sẽ chạy. Nếu là Gitlab server chạy thì nếu dự án mình thực hiện những lệnh không có thì sao, vì gitlab server thì cũng chỉ chứa gitlab và các program cho nó chứ đâu thể cài sẵn các program? Bên cạnh đó, mỗi lần chạy thì các thông tin liên quan đến file tạm có bị reset lại hay không?
Nếu bạn đi đến đây thì bạn đã đoán được là thực ra “cái thứ” thực thi các chỉ dẫn, câu lệnh trong file .gitlab-ci.yml không phải là Gitlab Server (là cái container đang chạy gitlab 9 mình start ở trên), mà đó chính là Gitlab Runner. Wow! Welcome to matrix!
Gitlab Runner là gì?
Gitlab Runner là thành phần cực kỳ quan trọng trong workflow Gitlab CI. Nếu không có Runner thì sẽ không có lệnh test, deploy nào được thực thi. Runner có nhiều loại, phân biệt dựa vào cái gọi là executor. Khi khởi tạo runner, bạn sẽ phải chọn nó là loại executor nào, và nó sẽ quyết định môi trường thực thi các câu lệnh trong file config ở trên. Bạn có thể tham khảo link https://docs.gitlab.com/runner/executors/ để biết sự khác nhau của các executor cũng như cách cài đặt, cấu hình chúng.
Do đặc thù hệ thống đã có docker, nên bên mình chỉ sử dụng executor loại Docker mà thôi. Và bên dưới là câu lệnh docker để start một Gitlab Runner.
docker run -d --name gitlab-runner --restart always \
-v /srv/gitlab-runner/config:/etc/gitlab-runner \
-v /var/run/docker.sock:/var/run/docker.sock \
gitlab/gitlab-runner:latest
Ở đây bạn sẽ thấy container này mount thư mục config ra ngoài, bởi vì mình muốn các cấu hình của runner không bị mất khi stop/remove container. Chỉ cần start lại là giữ được cấu hình. Ngoài ra, nó còn mount docker.sock vào bên trong container, đây là cách để executor loại docker có thể tận dụng lệnh docker bên ngoài host để thực hiện lệnh tạo container phụ trong quá trình runner chạy (test, deploy).
Start container lên chỉ là bước đầu, bởi vì lưu ý là tới thời điểm này, Runner này không có liên quan gì đến Gitlab server của chúng ta. Cần một bước link lại (gọi là register) runner này vào trong Gitlab server để mình có thể cho phép các dự án dùng runner trong quá trình CI/CD.
Xem link này https://docs.gitlab.com/runner/register/index.html để biết cách register runner này vào Gitlab Server.
Dưới đây là hình ảnh tham khảo bạn có thể dùng trong quá trình register 1 runner. Có 2 thông tin quan trọng là 1 cái URL và một random token. Và cái URL đặc biệt lưu ý là thường thêm /ci sau domain. Ví dụ ở trường hợp của mình setup là http://code.teamcrop.com/ci
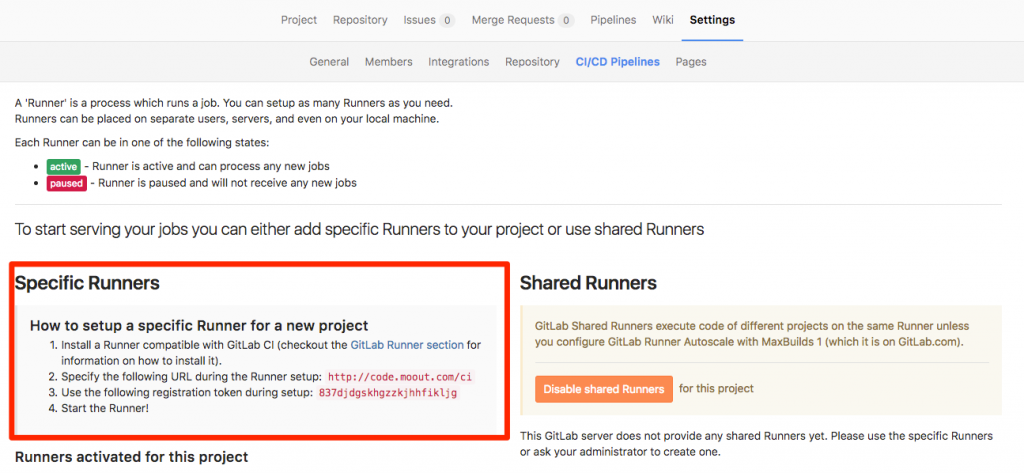
Sau khi Runner đã được gán vào Gitlab Server, bạn có thể enable runner này cho một hoặc nhiều dự án trong Gitlab. Hình bên dưới minh họa việc gán Runner vào dự án trong phần cài đặt Pipeline của Gitlab 9.
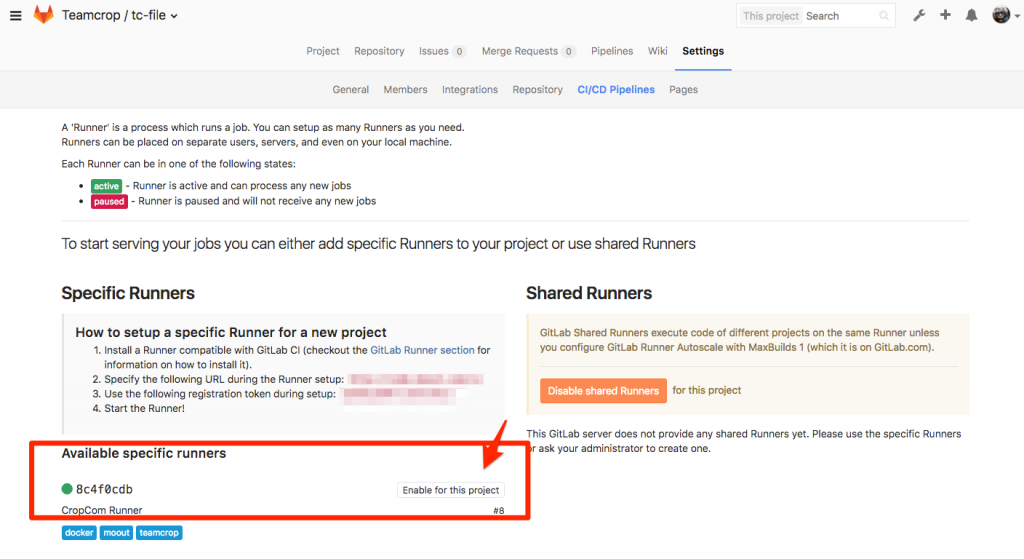
Đến đây hầu như đã cấu hình xong. Dự án đã kích hoạt 1 runner, và dự án đã có file .gitlab-ci.yml. Từ bây giờ, mỗi lần code được đưa lên thì runner sẽ thực thi test cũng như deploy dựa trên các câu lệnh được khai báo trong file cấu hình.
Khai báo biến để dùng trong các câu lệnh
Trong một số trường hợp, bạn có thể khai báo biến để có thể dùng trong các lệnh của runner. Có 3 nơi có thể cấu hình biến:
1. Cấu hình ngay bên trong file .gitlab-ci.yml
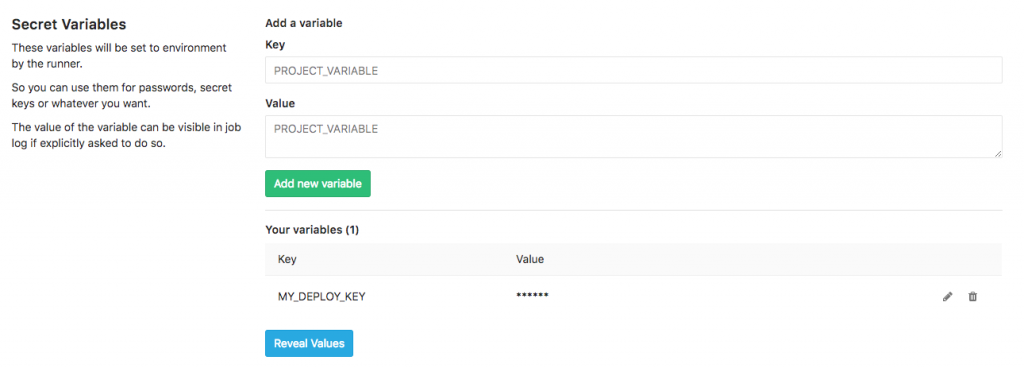
2. Cấu hình trong dự án. Vào Settings // CI/CD Pipelines, phần Secret variables (xem hình)
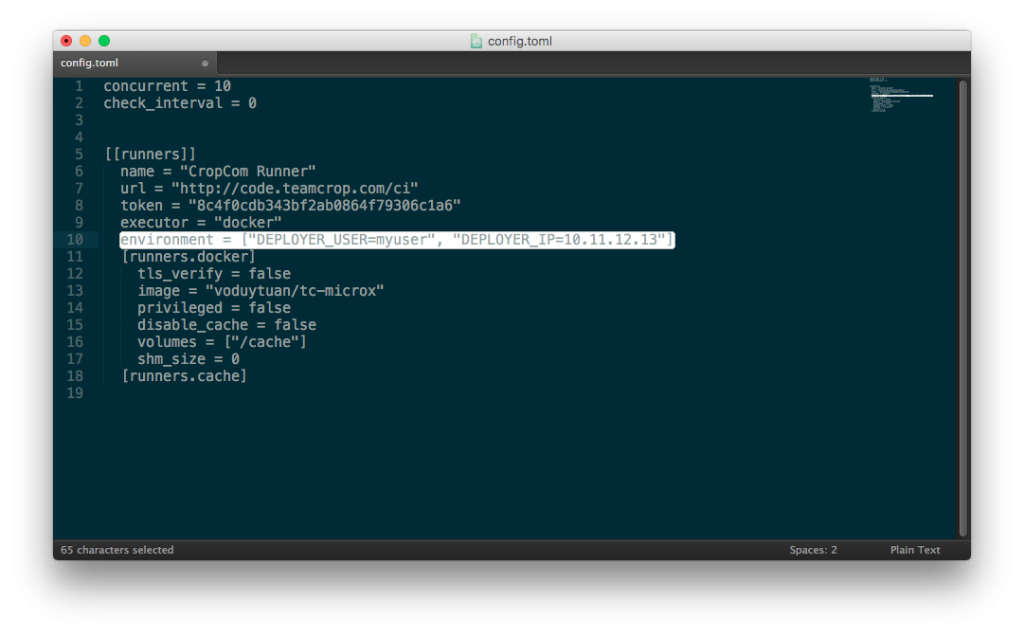
3. Cấu hình bên trong file config của runner. Bạn có nhớ lúc mình khởi tạo runner, có chỉ định một thư mục chứa config không, đây chính là nơi cấu hình chung cho runner này. Trong thư mục này sẽ có file là config.toml. Và bạn có thể gán biến trong cấu hình của từng runner. Cấu hình ở đây có một lợi thế là cứ runner này chạy sẽ nhận được biến đã cấu hình. Bạn không cần phải cấu hình nhiều lần ở từng dự án.
Ví dụ về một file .gitlab-ci.yml
Bên dưới là file cấu hình của một dự án trong hệ thống Microservices thuộc Teamcrop:
before_script:
- export "PATH=$PATH:/vendor/bin"
# Install ssh-agent if not already installed, it is required by Docker.
# (change apt-get to yum if you use a CentOS-based image)
- 'which ssh-agent || ( apt-get update -y && apt-get install openssh-client -y )'
# Run ssh-agent (inside the build environment)
- eval $(ssh-agent -s)
# For Docker builds disable host key checking. Be aware that by adding that
# you are suspectible to man-in-the-middle attacks.
# WARNING: Use this only with the Docker executor, if you use it with shell
# you will overwrite your user's SSH config.
- mkdir -p ~/.ssh
- '[[ -f /.dockerenv ]] && echo -e "Host *\n\tStrictHostKeyChecking no\n\n" > ~/.ssh/config'
variables:
# Change this base on project name
DEPLOYMENT_FOLDER_NAME: "tc-file"
test:
image: voduytuan/gitlab-php-ci
script:
- bash ./ci/phplint.sh ./src/
- phpcs --config-set ignore_errors_on_exit 1
- phpcs --config-set ignore_warnings_on_exit 1
- phpcs --standard=PSR2 --ignore=./src/index.php --error-severity=1 --warning-severity=8 -w --colors ./src/
- phpunit --configuration ci/phpunit.xml
dev:
image: voduytuan/gitlab-php-ci
stage: deploy
script:
- ssh-add <(echo "$DEPLOYER_BETA_KEY")
- echo "Deploy to $DEPLOYMENT_FOLDER_NAME"
- rsync -avuz -e "ssh -p 22" --exclude-from="ci/deploy_exclude.txt" $CI_PROJECT_DIR/src/ $DEPLOYER_BETA_USER@$DEPLOYER_BETA_IP:/teamcrop/services/$DEPLOYMENT_FOLDER_NAME/src
only:
- dev
production:
image: voduytuan/gitlab-php-ci
stage: deploy
script:
- ssh-add <(echo "$DEPLOYER_PRODUCTION_KEY")
- echo "Deploy to $DEPLOYMENT_FOLDER_NAME"
- rsync -avuz -e "ssh -p 22" --exclude-from="ci/deploy_exclude.txt" $CI_PROJECT_DIR/src/ $DEPLOYER_PRODUCTION_USER@$DEPLOYER_PRODUCTION_IP:/teamcrop/services/$DEPLOYMENT_FOLDER_NAME/src
only:
- master
when: manual
Trong ví dụ trên, phần test bên mình làm 3 việc:
– Chạy linter để đảm bảo sourcecode không bị lỗi cú pháp (phplint)
– Kiểm tra source code có theo chuẩn PSR2 hay không.
– Chạy PHPUnit
Còn về phần deploy thì có cấu hình 2 task là deploy dev và production. Ở task dev thì auto và lấy code từ branch dev. CÒn task production deploy từ branch master, tuy nhiên, có chế độ deploy manual, tức là nhấn thì mới deploy.

Về phần deploy source code thì sử dụng rsync để đẩy code từ repo sang server. Bạn sẽ thấy cú pháp giống nhau, chỉ khác là cấu hình đẩy đi đâu, với user nào và private key nào.
Do đặc thù của commandline nên sử dụng privatekey để đồng bộ code thông qua rsync. Do đó, trong project mình có cấu hình privatekey của user. Và bên server nhận (beta, production) mình đã đưa public key vào file authorized_keys. Bạn có thể tìm hiểu thêm về setup và generate cặp public/private key cho user deploy để hỗ trợ quá trình này tại link https://www.digitalocean.com/community/tutorials/how-to-set-up-ssh-keys–2. Hay ngắn gọn là thực hiện câu lệnh “ssh-keygen -t rsa -C “[email protected]” -b 4096″, nhập vài thông tin là bạn đã có public key (id_rsa.pub) để đem bỏ lên server (beta, production) và private key (id_rsa) đem bỏ vào setting biến môi trường.
—-
Dựa trên những kinh nghiệm CI/CD cho hệ thống Teamcrop.com theo mô hình microservice với hơn 40 repository lớn nhỏ, hy vọng bài viết này sẽ giúp được cho quá trình setup CI/CD cho hệ thống của bạn, cũng như tăng tốc quá trình phát triển dự án. Nếu thấy bài viết hay và hữu ích, hãy chia sẻ cho các anh em khác để cùng trao đổi và giao lưu.