Suốt tuần qua mình tập trung xử lý một bài toán khá “kinh điển” trong mô hình multi-tenant là đem đến “sự công bằng” (fairness) đối với các xử lý bất đồng bộ (async process). Nhận thấy vấn đề và giải pháp này sẽ giúp ích nhiều cho các anh em làm SaaS nên mình chia sẻ cách triển khai trong bài viết này.
Bài viết này dành cho những bạn đã từng thiết kế hệ thống theo mô hình bất đồng bộ như sử dụng Job Queue và đang có mô hình kinh doanh Multitenancy.

Vấn đề
Nếu bạn xây dựng hệ thống theo kiến trúc trúc Microservice thì bạn sẽ thường xuyên đối mặt với mô hình xử lý bất đồng bộ (async processing). Bởi vì đặc thù các service/process hoạt động tách biệt, để tránh ảnh hưởng tới thời gian chờ xử lý thì hầu hết hết các business logic phức tạp đều chạy bất đồng bộ (async). Trong trường hợp của Cropany là tính năng cập nhật tồn kho cho sản phẩm.
Theo như thiết kế hiện tại, tính năng “Số lượng tồn kho sản phẩm” được thiết kế theo pattern CQRS/ES. Tức là mọi thao tác liên quan đến tồn kho như Nhập kho (mua hàng), Xuất kho (bán hàng) đều có những record ghi nhận thao tác nhập xuất sản phẩm, sau đó sẽ kích hoạt API bất đồng bộ xử lý tính toán số tồn riêng của từng sản phẩm vào database (elasticsearch).
Trước đây, để tính toán tồn kho của sản phẩm, thì hệ thống có 1 queue chứa danh sách ID các sản phẩm cần cập nhật tồn kho. Khi 1 sản phẩm có tương tác nhập xuất thì ID sản phẩm này sẽ được đẩy vào queue, và worker sẽ lắng nghe trên queue này, các worker sẽ lấy đều đặn một số lượng nhất định ID (ví dụ: 10 ID/lần xử lý) và tiến hành tính toán số tồn và lưu vào database.
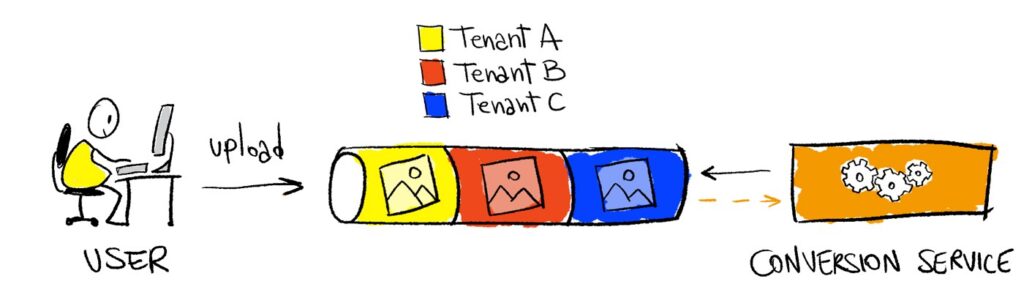
Do theo kiến trúc queue FIFO nên ID sản phẩm nào được đưa vào trước thì sẽ được worker xử lý trước và xử lý tuần tự cho tới khi queue này không còn message nào. Nếu mô hình của bạn là Single-tenancy thì sẽ không có vấn đề gì, nhưng nếu bạn đang theo mô hình Multi-tenancy và số lượng tenant khá lớn (ví dụ hơn 10,000 tenant) thì vấn đề có thể sẽ khá lớn.
Hãy hình dung, trong số các tenant, vào 1 thời điểm sẽ có tenant (gọi là Tenant-A) đẩy vào queue 5000 ID sản phẩm (họ đang nhập kho) và liền ngay sau đó có tenant khác (gọi là Tenant-B) chỉ xuất kho 1 sản phẩm (bán hàng). Theo như kiến trúc ban đầu thì queue sẽ có 5001 ID sản phẩm, và worker sẽ tiến hành lấy tuần tự số lượng ID cho phép xử lý (ví dụ 10 ID/lần xử lý) và như vậy, Tenant-B sẽ phải chờ worker xử lý hết 5000 message của Tenant-A mới đến lượt mình. Hiện tại không có sự ưu tiên nào giữa các tenant nên Tenant-B có thể bị coi là “thiệt thòi” hơn so với Tenant-A.

Trong ví dụ trên thì chỉ có 2 tenant, giả sử hệ thống multi-tenancy của bạn có 10,000 khách hàng và 10,000 tenant này đều nhập xuất kho với số lượng chênh lệch thì tenant cuối cùng đẩy ID sản phẩm vào queue sẽ phải chờ lâu nhất. Giải pháp hướng đến là đem lại “sự công bằng” cho các tenant nếu như mọi tenant đều có đặc quyền như nhau. Trong trường hợp của Cropany là khách hàng nào cũng miễn phí, dù dùng ít hay nhiều đều phải có sự công bằng và độ trễ ngang nhau khi sử dụng.
Giải pháp không hiệu quả
Giải pháp ban đầu có thể nghĩ ngay tới là đối với mỗi tenant thì mình sẽ có 1 queue riêng và tương ứng với mỗi queue sẽ có 1 worker lắng nghe và xử lý.
Về mặt performance thì giải pháp này không hiệu quả vì đồng thời có hàng ngàn worker tính toán tồn kho thì bottleneck sẽ rơi vào database chứa các giao dịch nhập xuất. Thay vì giải pháp cũ thì mỗi lần worker chỉ vào xử lý 1 số lượng nhất định và kiểm soát được (ví dụ 10 ID Sản phẩm / lần) thì bây giờ số lượng worker lớn làm tăng tải của quá trình xử lý, trong khi throughput của hệ thống chỉ cho phép 10 ID Sản phẩm / lần.
Về mặt kinh tế thì hoàn toàn không khả thi, tài nguyên để hỗ trợ chạy hàng ngàn worker và hàng ngàn queue không hề nhỏ và nó lại tăng tịnh tiến (linear) theo số lượng tăng thêm của tenant. Trong trường hợp của Cropany thì càng không thể vì chúng mình không thu phí khách hàng. Ngoài ra, sẽ có những tenant rất ít hoạt động, worker vẫn phải duy trì trong khi không có xử lý thì là một sự lãng phí.
Giải pháp của Cropany
Sau khi cân nhắc về hiệu suất, kinh tế và khả năng bảo trì nâng cấp thì mình quyết định sử dụng mô hình 1 queue, một worker như ban đầu để đảm bảo worker hoạt động đúng công suất cho phép và không gây áp lực lên hệ thống chung (các tính năng khác liên quan đến database). Tuy nhiên, khi phát sinh nhập xuất kho sản phẩm thì thay vì đẩy trực tiếp vào queue, các ID này sẽ được đưa vào một SET trong Redis, và mỗi tenant sẽ có một SET riêng (key riêng).
Giới thiệu nhanh về SET trong Redis, SET cho phép lưu trữ một danh sách các value không trùng. Trong trường hợp này, nếu ID sản phẩm đã tồn tại trong SET của tenant nào rồi thì khi phát sinh giao dịch, thêm 1 value vào SET mà đã tồn tại value này thì SET sẽ không lưu thêm, luôn đảm bảo value là không trùng.
Sau khi các tenant có các SET riêng thì mình viết một chương trình điều hướng nho nhỏ (nodejs), đều đặn đọc tất cả các SET này ra và cắt lát theo chiều dọc qua toàn bộ các tenant và đẩy vào queue thông thường. Theo cách này thì tenant dù có ít hay nhiều đều sẽ được xử lý song song theo từng phiên. Giả sử có 10k tenant và tenant nào cũng có ID sản phẩm cần xử lý thì bộ điều hướng này sẽ lấy mỗi tenant 1 ID và đẩy vào queue. Queue có thể chứa hàng triệu message, tuy nhiên, thứ tự các message khi thêm vào đã đảm bảo gần như công bằng cho các tenant.
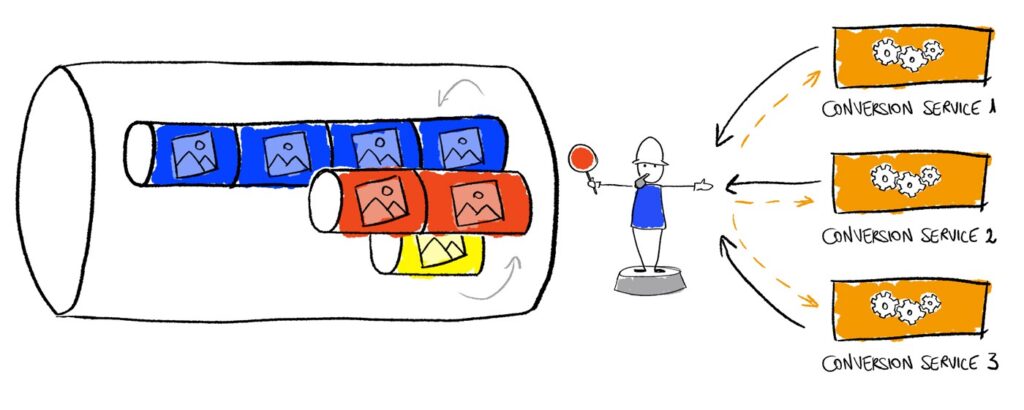
Sau khi đẩy vào queue thì bộ điều hướng này sẽ xoá ID khỏi SET trong Redis để tránh quá trình xử lý trùng lập.
Có một lưu ý nho nhỏ là bộ điều hướng này cần chạy theo interval (đơn vị giây) để đảm bảo có các tenant mới phát sinh SET mới thì vẫn được đưa vào queue chính. Hình minh hoạ bên dưới là quá trình mình visualize bộ điều hướng để debug quá trình cắt lát cho các bạn dễ hình dung.

Mở rộng
Như vậy, với kiến trúc này thì vẫn đảm bảo cơ chế scale hệ thống như là tăng cường throughput của worker, tăng số lượng worker nếu muốn xử lý nhanh hơn khi hệ thống cho phép.
Bên cạnh đó, nếu có cơ chế ưu tiên giữa các tenant thì có thể tăng cường queue riêng để áp dụng 1 số quyền lợi cho các tenant được ưu tiên.
UPDATED: Sau khi update lên UI thì mình chuyển sang SORTED SET thay vì SET nhé các đồng code. Sorted set sẽ lưu thêm score để đảm bảo độ ưu tiên và mình lấy timestamp làm score, còn SET thì không lưu thứ tự nên sẽ ko thể hiện rõ FIFO khi thêm vào SET.
Bài viết sử dụng một số hình ảnh từ bài viết https://medium.com/thron-tech/multi-tenancy-and-fairness-in-the-context-of-microservices-sharded-queues-e32ee89723fc cũng nói về đề tài fairness, các bạn có thể tham khảo cách tiếp cận khác của tác giả bài viết này.